Архитектура, таблицы, хранение
Введение в Greenplum¶
Что такое Greenplum¶
Greenplum — это аналитическая СУБД на основе PostgreSQL, построенная по принципу MPP (Massively Parallel Processing). Данные распределяются по нескольким сегментам, каждый из которых — отдельный экземпляр PostgreSQL.
Архитектура¶
Логически архитектура GP выглядит следующим образом.
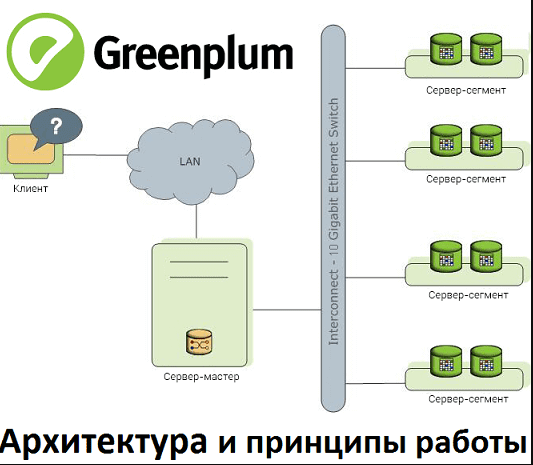
Мастер это входная точка для СУБД GP. Это экземпляр базы данных postgres к которому клиенты подключаются и отправляют свои SQL запросы. Мастер координирует работу с другими экземплярами базы данных системы, которые называются сегменты.
На мастере располагается глобальный системный каталог. Набор системных таблиц, которые содержат метаданные о всех объектах GP. Мастер не хранит каких-либо пользовательских данных. Все пользовательские данные хранятся на системе.
Функции мастера:
- авторизация соединений
- обработка SQL команд
- распределение нагрузки между сегментами
- координация результатов, возвращаемых каждым сегментом
- финальные операции над данными
- предоставляет конечный результат клиенту.
Системные таблицы хранятся не только на мастере, об этом будет подробнее в другой главе
Сегмент - отдельные экземпляры базы данных postgres, которые хранят определенную порцию пользовательских данных и выполняют основную часть работы при обработке запроса. Сегмент возвращает результат на мастер.
Сегменты работают на серверах, которые называются сегмент-хосты или ноды. На каждой ноде обычно располагается от 2 до 8 сегментов GP.
Ключ к оптимальной работе базы данных Greenplum это равномерно распределенные данные и рабочие нагрузки по большому количеству сегментов с одинаковой производительностью. Необходимо чтобы каждые из сегментов одновременно начинали работу над задачей и одновременно заканчивали.
Интерконнект - сетевой слой архитектуры GP. Обеспечивает взаимосвязь между мастером, сегментами и сетевой инфраструктурой.
1.Дистрибьюция¶
Дистрибуция это распределение данных между сегментами GP, для достижения максимальной производительности.
Принципы для хорошего ключа дистрибуции:
- равномерность распределения
- локальность операций (соединяемые таблицы имеют равный ключ дистрибуции)
Равномерное распределение + Учет особенностей данных (локальность операций) = Высокая производительность!
Виды дистрибуции:
| Тип | Описание |
|---|---|
| DISTRIBUTED BY ( |
Хеш-распределение. Конкретный сегмент выбирается на основе хешей, которые рассчитываются по полям, указанным в скобках. Рекомендуется использовать для таблиц, имеющих первичные ключи (PRIMARY KEY) либо столбцы с уникальными значениями (UNIQUE) — эти столбцы могут быть использованы в качестве ключа распределения (поля, на основе значений которого выбирается сегмент) |
| DISTRIBUTED REPLICATED | Распределение данных, при котором копия таблицы сохраняется на каждом сегменте кластера. Рекомендуется для небольших таблиц (например, таблиц-справочников). Позволяет избежать любых перемещений данных (Motion) при JOIN-запросах |
| DISTRIBUTED RANDOMLY | Случайное распределение данных с использованием алгоритма round-robin. Поскольку система выбирает сегменты случайным образом, равномерность распределения данных между ними не гарантируется. Рекомендуется для иных случаев — когда в таблицах нет столбцов с уникальными значениями, а размер таблиц достаточно большой. JOIN будет вызывать перераспределение данных |
Правила при выборе ключа дистрибуции
- Использование поля с большой селективностью (большое количество уникальных значений), как правило поля с идентификатором.
- Отсутствие null значений или значений по умолчанию.
Правильно ли вы выбрали ключ дистрибуции вам подскажет служебное поле gp_segment_id, существующее в каждой таблице – оно содержит номер сегмента, на котором хранится конкретная строка.
Перераспределение данных по текущему ключу, например, при добавление нового сегмента/
Ключ дистрибуции задаётся при создании таблицы:
-- создание таблицы с дистрибуцией по столбцу a
CREATE TABLE test_distr_key (
a INT PRIMARY KEY
, b TEXT)
DISTRIBUTED BY (a);
-- пересоздание ключа дистрибуции
ALTER TABLE test_distr_key DISTRIBUTED BY (b);
ALTER TABLE test_distr_key DISTRIBUTED BY RANDOMLY;
Рекомендации по распределению данных¶
| Раздел | Что делать? | Что будет, если нарушить рекомендацию? |
|---|---|---|
| Общие рекомендации | • Явно задавайте способ и ключ распределения при создании таблицы, в том числе для временных таблиц. • Используйте RANDOMLY-распределение для небольших таблиц, где нет хороших кандидатов на ключ распределения из одного атрибута. |
• Неравномерное распределение данных по сегментам. • Долго вычисляется хэш для ключа распределения из двух и более атрибутов. |
| Избегайте использования в качестве ключа распределения | • Атрибут, который будете часто указывать в предложении WHERE. • Атрибут с типом данных date, timestamp. |
• При фильтрации по ключу распределения участвует только часть сегментов. • Долго вычисляется хэш. |
| Старайтесь использовать в качестве ключа распределения | • Тип данных integer (предпочтительнее, чем string). • Столбец, который будете использовать как ключ соединения (JOIN ON). |
• Долго вычисляется хэш для string. • Выполнение JOIN потребует перераспределения строк между сегментами и неоптимального движения данных (motion). |
2.Партиционирование¶
Партиционирование или секционирование - логическое разделение таблицы на части по определенному критерию.
- Логически делит большую таблицу на части;
- значительно улучшает производительность запросов
- упрощает сопровождение базы данных (благодаря возможности хранить и перемещать данные)
Партиционирование - это метод оптимизации, при котором таблица делится на части на каждом сегменте с целью увеличения производительности запроса засчет выборочного сканирования.Партиционирование распространяется на все сегменты и выполняется на каждом сегменте одинаково.
Партиционирование не обязательно, в отличие от дистрибуции и является методом дополнительной оптимизации.
Партиции следует делать по полям, которые будут чаще использоваться в фильтрации данных (WHERE).
При создании партиционированный таблицы можно указать:
- Разные имена для каждой партиции;
- Отличающиеся диапазоны;
- Разные опции хранения (ориентация, компрессия);
Можно создать:
- Партицию по умолчанию (DEFAULT) для значений, не удовлетворяющих условиям других партиций
Нельзя:
- указать разные ключи дистрибуции для партиций одной таблицы;
- поменять тип партиционирования без пересоздания таблицы.
Цель партиционирования:
- исключение лишних партиций при выполнение запроса, чтобы оптимизатора быстрее читал нужные данные.
Когда следует использовать партиции ?
- Большая таблица
- Фильтры запросов (WHERE) исключают часть партиций
- Нужно "Скользящее окно" данных при периодической загрузке → архивировании
Как использовать? - Предпочитать RANGE, а не LIST - Партиционировать по часто используемому столбцу - Убедиться в исключении ненужных партиций в плане запроса (EXPLAIN) - выбирать наилучший способ физического хранения для разных партиций (например, по строкам/колонкам)
Не рекомендуется
- создавать большое количество партиций (благодаря MPP архитектуре GP эффективно обрабатывает операции чтения FULL SCAN)
- использовать дефолтную партицию (так как она просматривается при выполнении любого запроса)
- использовать многоуровневое партиционирование (так как это приводит к созданию большого количества партиций)
- секционировать по столбцу ключа дистрибуции!!
- создавать много партиций при колоночной ориентации (так как это приведет к большому количеству физических файлов на сегменте
количество физических файлов = сегменты * столбцы * партиции)
2.1. Виды партиционирования¶
| вид партицирования | синтаксис |
|---|---|
| по диапазону значений | PARTITION BY RANGE |
| по списку значений | PARTITION BY LIST |
| многоуровневое | PARTITION BY ... SUBPARTION BY ... |
2.2. Примеры стратегии партиционирования и хранения данных¶
Наиболее свежие данные хранятся без компрессии. Старые данные хранятся с более сильными алгоритмами сжатия.
Также сами партиции организованы по разному для более быстрой работы новые данные партицируются по 1 дню (если данных за день огромное количество), обычно партиции по месяцам или неделям.
Пример стратегии партиционирования и хранения данных¶
| Глубина | Ориентация | Партиции | Способ хранения | Компрессия |
|---|---|---|---|---|
| Сегодня | Row | день | HEAP | – |
| -3 мес | Row | мес | AO | Низкая (×2,5), Zstd |
| -12 мес | column | год | AO | Средняя (×7), Zstd |
| -24 мес | column | год | AO | Высокая (×15), Zstd |
| -120 мес | - | год | Внешняя таблица, например S3 |
2.3. Пример синтаксиса партиций¶
Добавление партиции
-- добавление партиции
ALTER TABLE card_list ADD PARTITION n_a values('NA');
ALTER TABLE card_list ADD PARTITION new
START('2016-01-01'::date) END('2017-01-01'::date)
WITH(appendonly='true', comresstype=zlib, compesslevel='9');
ALTER TABLE card_list ADD DEFAULT PARTITION other;
Изменение названия партиции
очистить партицию на определенную дату
ALTER TABLE table_prt_mixed TRUNCATE PARTITION FOR ('2019-04-28'::date);
Удаление партиции
-- дроп обычный партиции
ALTER TABLE card_list DROP PARTITION n_a IF EXIST;
-- дроп дефолтной партиции
ALTER TABLE card_list DROP DEFAULT PARTITION IF EXIST;
Изменение опции хранения
Создать таблицу с нужной опцией хранения → вставить нужные данные из партиции → заменить всю прежнюю партицию на только что созданую партицию
CREATE TABLE jan21 (LIKE sales) WITH(appendoptimized=true);
INSERT INTO jan21 SELECT * FROM sales_1_prt_1;
ALTER TABLE sales EXCHANGE PARTITION FOR (DATE '2021-01-01')
WITH TABLE jan21;
Разделение партиции
-- разделение партиции за январь на 2 партиции с 1 января по 15 января, во второй с 16 по 31 января
ALTER TABLE sales SPLIT PARITION FOR ('2021-01-01')
AT ('2021-01-16')
INTO (PARTITION jan21_1_to15, PARTITION jan21_16to31);
-- вариант для дефолт партиции (нужно указать второй партицией дефолт партицию)
ALTER TABLE sales SPLIT DEFAULT PARTITION
START ('2021-01-01') INCLUSIVE
END ('2021-02-01') EXCLUSIVE
INTO (PARTITION jan21, default partition);
2.4 Субпартиции¶
На практике Субпартиции используются редко, по сути это партиции для партиций.
Создание и изменение шаблонов субпартиций
CREATE TABLE seles (trans_id int, date date, amount decinal(9,2) region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE(date)
SUBPARTITION BY LIST (region)
SUBPARTITION TEMPLATE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe'),
DEFAULT SUBPARTIOTION other_regions)
(START (date '2014-01-01') INCLUSIVE
END (date '2014-04-01') EXCLUSIVE
EVERY (INTERVAL '1 month'));
При добавлении новой партиции, она автоматически будет разделена на субпартиции. Пример скрипта добавления партиции
При необходимости шаблона субпартиции можно изменить
ALTER TABLE sales SET SUBPARTITION TEMPLATE
( SUBPARTITION usa VALUES ('usa'),
SUBPARTITION asia VALUES ('asia'),
SUBPARTITION europe VALUES ('europe'),
SUBPARTIOTINO africa VALUES ('africa'),
DEFAULT SUBPARTIOTION other_regions);
на уже созданные таблицы это не повлияет, но созданные партиции заново, будут создавать по новому шаблону.
Удаление субпартиции
2.5. Просмотр информации о партициях¶
Сведения о партициях можно посмотреть в специальных представлениях.
pg_catalog.pg_partitions - содержит информацию о партиционированных таблицах и их иерархии
pg_catalog.pg_partitions_columns - содержит информацию о колонках, которые используются для партиционирования
3. Таблицы¶
Создание таблицы
CREATE TABLE orders
(
order_num integer,
name text,
price numeric
);
-- или с указанием схемы
CREATE TABLE test.orders
(
order_num integer,
name text,
price numeric
);
Таблица по умолчанию создается в схеме public.
В GP невозможно удалить таблицу, не удалив все зависимые объекты (имеется в виду представления view, которые собираются на основе этой таблицы).
GP поддерживает полиморфное хранение данных, часть таблицы может храниться в строках, часть в колонках, причем с разными видами компрессии.
Копирование таблиц¶
Возможно целиком скопировать таблицу (т.е. с данными) при помощи конструкции:
Копирование только структуры таблицы (т.е. без данных), копирует также все ограничения, типы данных, способ распределеления. Но свойства хранения (например, тип партиционирования или метод хранения не копируется).
Метод хранения данных (HEAP and APPEND-OPTIMIZED)¶
GP поддерживает два метода хранения данных: HEAP (куча) и Append-Optimized таблицы
Heap-таблицы¶
Тип таблиц HEAP используется по умолчанию и является стандартной физической структурой со строковой ориентацией.
В каких случаях HEAP?
- Небольшой объем данных (в большинстве случаев это менее 300к строк или менее 30-100 мб данных ❗может разниться от настроек кластера и вашей БД);
- чисто выполнение операций UPDATE, DELETE;
- единичные операции вставки (INSERT);
- OLTP нагрузка (параллельные операции удаления, обновления, вставки данных);
- Поддерживает уникальные индексы (UNIQUE INDEX) и ограничение первичного ключа (PRIMARY KEY)
APPEND-OPTIMIZED таблицы¶
Append-Optimized таблицы - уникальны для GP.
Возможности: - можно выбрать ориентацию, строчная или колоночная - можно сжимать применяя различные алгоритмы компрессии - менее ресурсоемкие (например, сбор статистики может быть выполнен инкрементально и таким образом быстрее)
Ограничения:
- для редко изменяемых данных, вставка происходит батчами
- прирост производительности для больших таблиц
- не поддерживает уникальные индексы (UNIQUE INDEX) и ограничение первичного ключа (PRIMARY KEY)
Когда выбирать:
- много данных в таблицах (как правило это таблица фактов);
- создаются однажды, и далее к ней выполоняются запросы или добавляют данные батчами (OLAP нагрузка)
Как выбрать ориентацию в AOP таблицах?
Строковая ориентация:
- множественное обновление
- частые операции вставки
- частая выборка одновременно большого количества столбцов
Колоночная ориентация - при выборке используется малое количество столбцов; - выполняются агрегирующие операции над малым количеством столбцов; - есть единичные столбцы, которые часто обновляются без изменения остальных значений в строке. - занимает меньшее количество места таблицей (примерно на 30%)
Методы хранения таблиц в Greenplum¶
| Метод | Тип | Хранение | Уникальность | Компрессия | Нагрузка | Запросы |
|---|---|---|---|---|---|---|
| HEAP | ROW | Строковое | UNIQ, INDEX, PK | — | OLTP | — |
| APPEND-OPTIMIZED | ROW | Строковое | — | ZSTD, ZLIB | OLAP | Все столбцы |
| APPEND-OPTIMIZED | COLUMN | Колоночное | — | ZSTD, ZLIB, RLE | OLAP | Часть столбцов |
4. Представления¶
Представление - объект базы данных, который по сути представляет из себя сохраненный запрос. При обращении пользователя к представлению ему возвращается результат данного запроса. Представления хранят не сами данные, а только ссылки на них.
Создание:
Изменение:
Удаление:
❗ Если необходимо удалить базовые таблицы (на которых строится представление), то их необходимо удалять использую CASCADE
GP позволяет переименовать базовые таблицы без изменения представлений.
Использование представлений¶
- С помощью представлений можно обеспечить дополнительный уровень безопасности данных.
- Ограничение доступа пользователей только к части таблиц.
- Можно скрыть сложность запросов и сложность структур базовых таблиц.
- Разделение схем представления и хранения данных, так как возвращает не противоречивые структуры данных, даже если исходные таблицы претерпели изменения по структуре или переименовались.
- Представлениям не требуется дискового пространства.
Материализованные представления¶
Главная особенность материализованных представлений:
- Сохраняется результат запроса на диске
- Можно обращаться, как к обычной таблице
- Содержит данные на момент последнего обновления
- Обновляется по запросу REFRESH MATERIALIZED VIEW
- Значительно ускоряет доступ к данным, засчет предварительного расчета
Пример создания
Для удаления:
В Greenplum для материализованных представлений есть возможность указывать опции хранения, как для обычных таблиц:
- задать поле дистрибуции;
- метод хранения (HEAP or AOP);
- метод компресии;
- таккже для материализованного представления можно создать индекс, как для обычной таблицы.
Обновление материализованных представлений¶
Стандартное обновление данных, удаляет старые данные, всталяет новые
Способ с WITH NO DATA - удалит данные в мат. представлении и приведет его в состояние unscannable. Запросы к нему будут возвращать ошибку, до тех пор пока мат. представление не будет обновлено стандартным способом.